
Sentinel、Nacos Config 和 Sleuth 实现了服务容错、配置管理和分布式链路追踪
一、创建项目
我们创建一个新项目,利用一阶段代码对项目进行改造,通过Nacos Config动态配置实现动态修改ProducerController中的的setPrefix值,使用Sentinel替换一阶段中Hystrix实现降级,并对接口进行限流,利用Sleuth对接口异常进行链路追踪更方便定位异常。
附上项目源码地址
二、NacosConfig动态配置
2.1 添加依赖
在producer-serv 的 pom 文件,在 pom 中添加以下两个依赖项。
<!-- 添加Nacos Config配置项 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- 读取bootstrap文件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
Nacos 既能用作配置管理也能用作服务注册,如果你想要引入 Nacos 的服务发现功能,需要添加的是 nacos-discovery 包;而如果你想引入的是 Nacos 的配置管理功能,则需要添加 nacos-config 包。
第二个依赖项是为了让程序在启动时能够加载本地的 bootstrap 配置文件,因为 Nacos 配置中心的连接信息需要配置在 bootstrap 文件,而非 application.yml 文件中。在 Spring Cloud 2020.0.0 版本之后,bootstrap 文件不会被自动加载,你需要主动添加 spring-cloud-starter-bootstrap 依赖项,来开启 bootstrap 的自动加载流程。
为什么集成 Nacos 配置中心必须用到 bootstrap 配置文件呢?这就要说到 Nacos Config 在项目启动过程中的优先级了。如果你在 Nacos 配置中心里存放了访问 MySQL 数据库的 URL、用户名和密码,而这些数据库配置会被用于其它组件的初始化流程,比如数据库连接池的创建。为了保证应用能够正常启动,我们必须在其它组件初始化之前从 Nacos 读到所有配置项,之后再将获取到的配置项用于后续的初始化流程。
2.2 配置Nacos Config
resource 文件夹中创建 bootstrap.yml 配置文件
spring:
# 必须把name属性从application.yml迁移过来,否则无法动态刷新
application:
name: producer-serv
cloud:
nacos:
config:
# nacos config服务器的地址
server-addr: 127.0.0.1:8848
file-extension: yml
# prefix: 文件名前缀,默认是spring.application.name
# 如果没有指定命令空间,则默认命令空间为PUBLIC
namespace: dev
# 如果没有配置Group,则默认值为DEFAULT_GROUP
group: DEFAULT_GROUP
# 从Nacos读取配置项的超时时间
timeout: 5000
# 长轮询超时时间
config-long-poll-timeout: 10000
# 轮询的重试时间
config-retry-time: 2000
# 长轮询最大重试次数
max-retry: 3
# 开启监听和自动刷新
refresh-enabled: true
# Nacos的扩展配置项,数字越大优先级越高
extension-configs:
- dataId: redis-config.yml
group: EXT_GROUP
# 动态刷新
refresh: true
- dataId: rabbitmq-config.yml
group: EXT_GROUP
refresh: true
带动态配置的值,先给defaultValue附上默认值,防止动态读取时异常:
@Value("${defaultValue:Hello}")
private String setPrefix;
在ProducerController上添加RefreshScope注解
@RefreshScope
public class ProducerController {}
添加配置文件到 Nacos Config Server
首先,我们在本地启动 Nacos 服务器,打开配置管理模块下的“配置列表”页面,再切换到“开发环境”命名空间下(即 dev 环境)。点击右上角的+添加配置producer-serv,添加上defaultValue的值


2.3 启动项目测试
访问customer/changeValue接口发现值已经不是默认Hello了,尝试将值修改成How old are you,发现值也改变了


三、Sentinel限流
3.1运行 Sentinel 控制台
我们可以从Sentinel 官方 GitHub的 Release 页面下载可供本地执行的 jar 文件,为了避免版本不一致导致的兼容性问题,我推荐你下载 1.8.2.Release 版本。在该版本下的 Assets 部分,你可以直接下载 sentinel-dashboard-1.8.2.jar 这个文件。
下载好文件之后,你可以使用命令行进入到这个 jar 包所在的目录,然后就可以直接执行下面这行命令启动 Sentinel 控制台了。
java -Dserver.port=8079 -Dcsp.sentinel.dashboard.server=localhost:8079 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.2.jar
这行命令以 8080 为端口启动了 Sentinel 控制台,启动成功后你可以在浏览器直接访问 localhost:8080 地址。当你看到登录界面,你就可以使用默认账号进行登录了,登录名和密码都是 sentinel。登陆成功之后你就可以进入到 Sentinel 控制台主页面,在左侧的导航栏会列出当前已经接入 Sentinel 的所有应用,这里默认展示的 sentinal-dashboard 应用其实就是控制台程序本尊了。
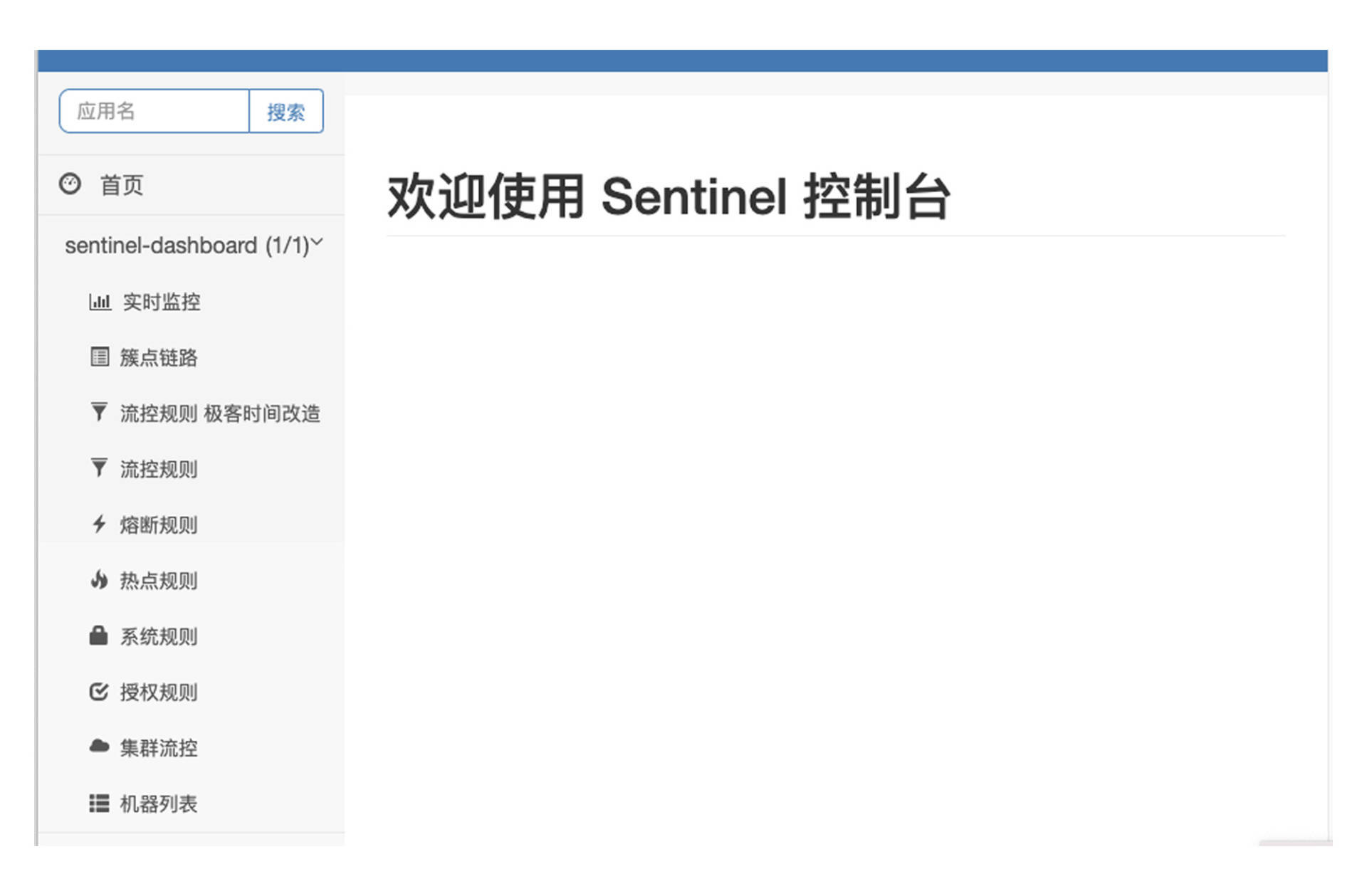
3.2 将微服务接入到 Sentinel 控制台
首先,你需要把 Sentinel 的依赖项引入到项目里。你只用将 spring-cloud-starter-alibaba-sentinel 组件加入到 customer-serv。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
然后,你需要做一些基本的配置,将应用直连到 Sentinel 控制台。这一步也非常简单,你只需要在项目的 application.yml 文件中加入下面的 sentinel 属性就可以了,具体代码在这里:
spring:
cloud:
sentinel:
transport:
# sentinel api端口,默认8719
port: 8719
# dashboard地址
dashboard: localhost:8079
在上面的代码中,port 属性是 Sentinal API 的默认端口,默认值是 8719;而 dashboard 属性则是指向了 Sentinel 控制台的地址,这里我们填写的是 localhost:8079。
最后,你还需要在代码中使用 Sentinel 注解对资源进行标记。在 Sentinel 的世界中,一切都是以“资源”的方式存在的。Controller 类里面写的 API 也是资源,这个资源便是 Sentinel 要守护的对象。
Sentinel 会为 Controller 中的 API 生成一个默认的资源名称,这个名称就是 URL 的路径。
首先在CustomerController中添加一个新的接口addCharacter,实际调用的还是producer-serv的addPrefix方法,并指定限流后的降级处理类以及方法。
@GetMapping("/addCharacter")
@SentinelResource(value = "addCharacter",
blockHandlerClass = SentinelBlockHandler.class,
blockHandler = "addCharacterBlock")
public String addCharacter(@RequestParam("name") String name){
return customerService.changeValue(name);
}
@GetMapping("/changeValue")
@SentinelResource(value = "changeValue")
public String changeValue(@RequestParam("name") String name){
return customerService.changeValue(name);
}
添加一个SentinelBlockHandler类,用于处理限流后的降级逻辑
@Slf4j
public class SentinelBlockHandler {
public static String addCharacterBlock(String name, BlockException blockException) {
log.info("addCharacter接口被限流");
return name;
}
}
在上面的代码中,我使用 SentinelResource 注解对 addCharacter方法做了标记,将它们的资源名称设置为方法名。除此之外,在 addCharacter方法中,我还使用了注解中的blockHandler 属性为当前资源指定了限流后的降级方法,如果当前服务抛出了 BlockException,那么就会转而执行这段限流方法。重启项目后(注意项目重启后,之前配置的规则将清除,后面有对应的解决方案),最后还需要在sentinel中添加名为addCharacter的流控规则

3.3 设置限流规则
Sentinel 支持三种不同的流控模式,分别是直接流控、关联流控和链路流控。
-
直接流控:直接作用于当前资源,如果访问压力大于某个阈值,后续请求将被直接拦下来;
-
关联流控:当关联资源的访问量达到某个阈值时,对当前资源进行限流;
-
链路流控:当指定链路上的访问量大于某个阈值时,对当前资源进行限流,这里的“指定链路”是细化到 API 级别的限流维度。
3.3.1 直接流控
以addCharacter接口为例,在sentinel中的流控规则中添加一个规则。资源名称设置成@SentinelResource中value的值,其中QPS就是每秒查询次数Queries-per-second,设置为2。测试一下是否生效,访问addCharacter接口,疯狂点刷新后,只返回了name值,并且后台打印了限流日志,和SentinelBlockHandler中配置的一致。


3.3.2 关联流控
如果两个资源之间有竞争关系,比如说,它们共享同一个数据库连接池,这时候你就可以使用“关联流控”对低优先级的资源进行流控,让高优先级的资源获得竞争优势。
对之前的addCharacter改成关联流控,QPS设置为2,注意关联资源changeValue为高优先级资源,本身为低优先级资源,关联限流的阈值判断是作用于高优先级资源之上的,但是流控效果是作用于低优先级资源之上。意思就是如果高优先级资源changeValue的访问频率达到了每秒两次,那么低优先级资源就会被限流。

这里测试不太方便,需要一秒内点击两个接口,可以将QPS调成1,会更好测试。大致流程就是点击changeValue接口,然后快速刷新addCharacter接口,会发现addCharacter接口被限流。
3.3.3 链路流控
如果在一个应用中,对同一个资源有多条不同的访问链路,那么我们就可以应用“链路流控”,实现 API 级别的精细粒度限流。一张图帮你理解链路流控的作用点。
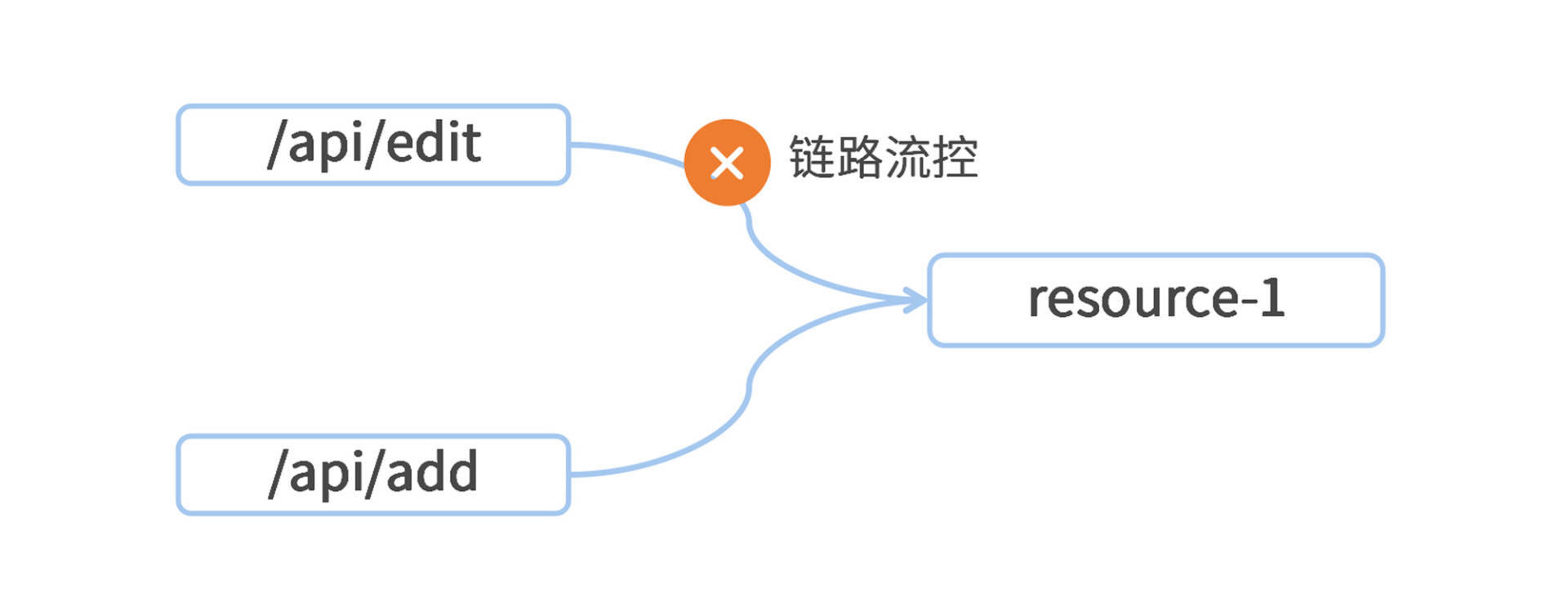
在上面的图里,一个服务应用中有 /api/edit 和 /api/add 两个接口,这两个接口都调用了同一个资源 resource-1。如果我想只对 /api/edit 接口流进行限流,那么就可以将“链路流控”应用在 resource-1 之上,同时指定当前流控规则的“入口资源”是 /api/edit。
链路限流需要注意两点:
-
只针对从指定链路访问到本资源的请求做统计,判断是否超过[阈值]
-
关闭默认的链路:web-context-unify: false #默认将调用链路收敛
对CustomerServiceImpl实现类进行改造
@SentinelResource(value = "changeValueLimit", blockHandler = "changeValueFlow")
public String changeValue(String name) {
String res = "";
res = producerService.addPrefix(name);
return res;
}
public String changeValueFlow(String name, BlockException blockException) {
log.info("changeValue接口被限流");
return name;
}
重启访问项目可以看到链路结构

然后给changeValueLimit配置链路流控规则

上面配置标识,当changeValueLimit超过1,只对addCharacter接口限流,而changeValue接口不受影响。最后测试结果预想的一样。注意,如果链路有问题,可能是web-context-unify: false失效,可以通过配置类的方式配置。
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-web-servlet</artifactId>
</dependency>
package com.wz.producerserv;
import com.alibaba.csp.sentinel.adapter.servlet.CommonFilter;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @className:FilterContextConfigSentinel
* @auther: WangZhen
* @description: Sentinel配置链路流控
* @since: 2022/4/26 12:39
*/
@Configuration
public class FilterContextConfigSentinel {
/**
* @NOTE 在spring-cloud-alibaba v2.1.1.RELEASE及前,sentinel1.7.0及后,关闭URL PATH聚合需要通过该方式,spring-cloud-alibaba v2.1.1.RELEASE后,可以通过配置关闭:spring.cloud.sentinel.web-context-unify=false
* 手动注入Sentinel的过滤器,关闭Sentinel注入CommonFilter实例,修改配置文件中的 spring.cloud.sentinel.filter.enabled=false
* 入口资源聚合问题:https://github.com/alibaba/Sentinel/issues/1024 或 https://github.com/alibaba/Sentinel/issues/1213
* 入口资源聚合问题解决:https://github.com/alibaba/Sentinel/pull/1111
*/
@Bean
public FilterRegistrationBean sentinelFilterRegistration() {
FilterRegistrationBean registration = new FilterRegistrationBean();
registration.setFilter(new CommonFilter());
registration.addUrlPatterns("/*");
// 入口资源关闭聚合
registration.addInitParameter(CommonFilter.WEB_CONTEXT_UNIFY, "false");
registration.setName("sentinelFilter");
registration.setOrder(1);
return registration;
}
}
3.4 实现针对调用源的限流
这个实现过程分为两步。第一步,你要想办法在服务请求中加上一个特殊标记,告诉 producer-serv服务是谁调用了你;第二步,你需要在 Sentinel 控制台设置流控规则的针对来源。
首先,你需要对 customer-serv 服务的 OpenFeign 组件做一点手脚,将调用源的应用名加入到由 OpenFeign 组件构造的 Request 中。我们可以借助 OpenFeign 的 RequestInterceptor 扩展接口,编写一个自定义的拦截器,在服务请求发送出去之前,往 Request 的 Header 里写入一个特殊变量,你可以参考我这段代码。
@Configuration
public class OpenfeignSentinelInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
template.header("HeaderFlagSentinelSource", "customer-serv");
}
}
在上面的代码中,我在 Customer 服务中新建了一个 OpenfeignSentinelInterceptor 的类,继承自 RequestInterceptor 并实现了其中的 apply 方法。在这个方法里,我向服务请求的 header 里加入了一个 SentinelSource 属性,对应的值是当前服务的名称 coupon-customer-serv。这就是我要传递给下游服务的“来源标记”。
接下来,需要在 producer-serv服务中识别来自上游的标记,并将其加入到 Sentinel 的链路统计中。先将Sentinel引入,可以借助 Sentinel 提供的 RequestOriginParser 扩展接口,编写一个自定义的解析器。你可以参考我这里的代码实现。
@Component
@Slf4j
public class SentinelOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
log.info("request {}, header={}", request.getParameterMap(), request.getHeaderNames());
return request.getHeader("HeaderFlagSentinelSource");
}
}
在上面的代码中,我在 producer-serv服务中新建了一个 SentinelOriginParser 的类,它实现了 RequestOriginParser 接口中的 parseOrigin 方法。在方法中,我们从服务请求的 Header 中获取 SentinelSource 变量的值,作为调用源的 name。对addPrefix接口进行改造,这里就简单写,直接通过blockHandler指定降级方法,将addPrefixBlock方法写在ProducerController中。
@GetMapping("/addPrefix")
@SentinelResource(value = "addPrefix", blockHandler = "addPrefixBlock")
public String addPrefix(@RequestParam("name") String name) {
return producerService.addPrefix(name, setPrefix);
}
public String addPrefixBlock(String name, BlockException blockException) {
log.info("addPrefix接口被限流");
return name;
}
开始测试,将addPrefix中设置针对来源添加customer-serv,发现通过customer-serv会被限流,如果通过producer-serv访问自己,则不会。



3.5 Sentinel 的流控效果
Sentinel 总共支持三种流控效果,分别是快速失败、Warm Up 和排队等待。
快速失败,Sentinel 默认的流控效果就是快速失败,前面做的实战改造都是采用了这种模式。这种流控效果非常好理解,在快速失败模式下,超过阈值设定的请求将会被立即阻拦住。
第二种流控效果 Warm Up 则实现了“预热模式的流控效果”,这种方式可以平缓拉高系统水位,避免突发流量对当前处于低水位的系统的可用性造成破坏。
举个例子,如果我们设置的系统阈值是 QPS=10,预热时间 =5,那么 Sentinel 会在这 5 秒的预热时间内,将限流阈值从 3 缓慢拉高到 10。为什么起始阈值是 3 呢?因为 Sentinel 内部有一个冷加载因子,它的值是 3,在预热模式下,起始阈值的计算公式是单机阈值 / 冷加载因子,也就是 10/3=3。
在排队等待模式下,超过阈值的请求不会立即失败,而是会被放入一个队列中,排好队等待被处理。当然了,每个请求的排队时间可不是永恒的,一旦请求在队列中等待的时间超过了我们设置的超时时间,那么请求就会被从队列中移除。
四、Sentinel熔断降级
4.1 熔断降级
我们先将之前的Hystrix的降级处理逻辑去除,防止异常。
将customer-serv中的ProducerService的@FeignClient降级逻辑,并移除fallback包,移除Hystrix相关pom文件
@FeignClient(value="producer-serv", path = "/producer")
public interface ProducerService {
@GetMapping("/addPrefix")
public String addPrefix(@RequestParam("name") String name);
}
添加SentinelFallBack类
@Slf4j
public class SentinelFallBack {
public static String changeValueFallBack(String name) {
log.info("changeValue接口异常,服务被降级");
return name;
}
}
给changeValue接口添加属性fallbackClass属性指定降级类,通过fallback指定降级方法
@GetMapping("/changeValue")
@SentinelResource(value = "changeValue",
fallbackClass = SentinelFallBack.class,
fallback = "changeValueFallBack")
public String changeValue(@RequestParam("name") String name){
return customerService.changeValue(name);
}
另外,我在producer-serv服务中的ProducerServiceImpl保留一段逻辑,用于模拟异常情况
public String addPrefix(String name, String prefix) {
if ("FEIWU".equals(name)) {
throw new NullPointerException();
}
return prefix + "," + name;
}
4.2 添加熔断策略
你会看到,Sentinel 的熔断规则有 3 种,分别是异常比例、异常数和慢调用比例。我们可以分别看看它们是如何使用的。
4.2.1 异常比例策略
首先,你可以指定以“异常比例”为熔断开关的判断逻辑。在 10 秒的统计窗口内,如果异常调用的比例超过了 60%,并且满足请求数量 >=5,就开启一段为期 5 秒的熔断时间。

在设置过程中,你一定要注意界面上显示的时间单位。“熔断时长”的时间单位是秒,而“统计窗口”的时间单位是毫秒,这两者很容易弄混。
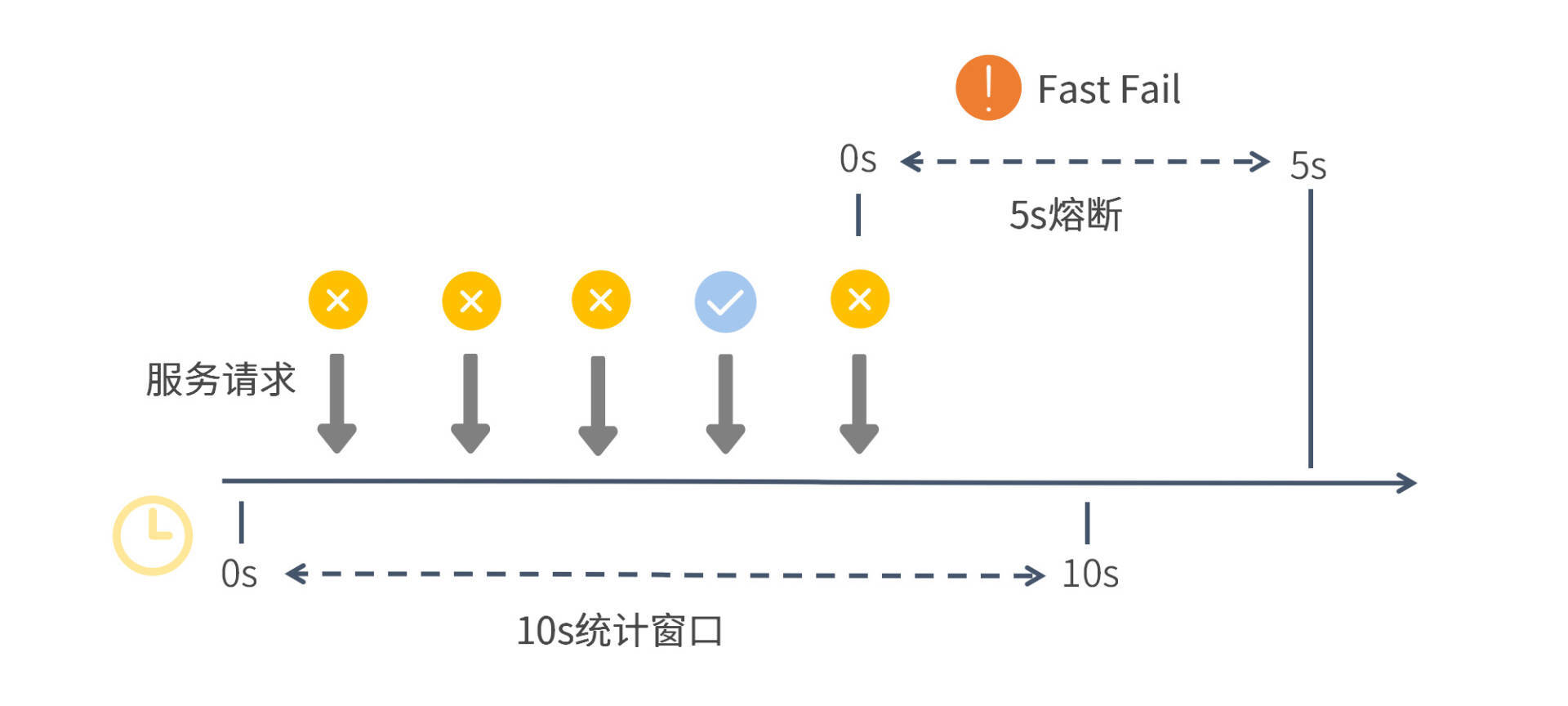
从图中你可以看出,Sentinel 底层通过一段跨度为 10 秒的滑动窗口来统计服务调用情况。在这段窗口时间内,前三个服务请求全部失败,这时失败率已经达到 100%,大大超过了我们定义的 60% 的阈值,但是熔断开关却没有打开,这是因为统计窗口的最小请求数还没有达到设定值 5。
之后又有两个请求被处理,一个成功一个失败,这时请求个数已经达到了 5,失败率是 80%,那么 Sentinel 就开启了一段 5 秒的熔断时间。在这段时间内,所有来访请求都不会得到真实的执行,而是转而执行降级逻辑。
4.2.2 异常数策略
“异常数”熔断规则和前面我们设置的异常比例熔断规则几乎一样,唯一的区别就是“异常数”的判定条件是统计窗口内发生异常的个数,而不是去统计异常请求的比例。在下面这张图里,我设置了一个基于异常数判定的规则,即 changeValue请求在 10 秒内异常数 >2,则触发 5 秒的熔断窗口。

在这里我想提醒你注意,熔断器开启的判定条件是异常数 >2,注意这里是大于2 而不是大于等于 2。也就是说,即便在窗口期内你调用了 5 次接口,其中有 2 个接口发生了异常,那么你也要等下一次失败调用发生之后,才能满足异常数大于 2 的判定条件,触发熔断。
4.2.3 慢调用策略
在下面的图中,我设定了一条慢调用判定条件。在 10 秒的统计窗口内,如果响应时间大于 1000ms 的请求所占总请求数量的比例超过了 0.4,并且请求总数量 >=5,此时将触发 Sentinel 的熔断开关,开启 5 秒的熔断窗口。

需要注意的是,当服务请求超过设置的最大响应时间,Sentinel 只是会将该次请求作为一次慢响应加入到统计数据里,并不会将这个请求直接阻塞掉。因此,这里的最大 RT 只是一个用来做统计的条件参数,而不是超时判定的参数。
在真实业务中,“慢调用”是一个关键侦测指标,拿阿里系的应用监控为例,业务层有 RT 监控,DB 层也有慢 SQL 监控,目的就是将可能的服务雪崩扼杀于摇篮之中。因为当服务响应逐渐变慢的时候,说明集群所承接的业务流量也在同步增加,当 RT 越来越大直到达到一个阈值的时候,集群的吞吐量必然会迎来一个拐点。这个拐点也是全链路压测时要获取的一个关键指标,它是集群吞吐量的极限。
4.3 Sentinel 熔断开关的状态转换
Sentinel 的熔断器会在开启、关闭和半开这三种逻辑状态之间来回切换,为了方便你理解整个过程,我画了一张图来解释熔断器的状态变化,你可以参考一下。
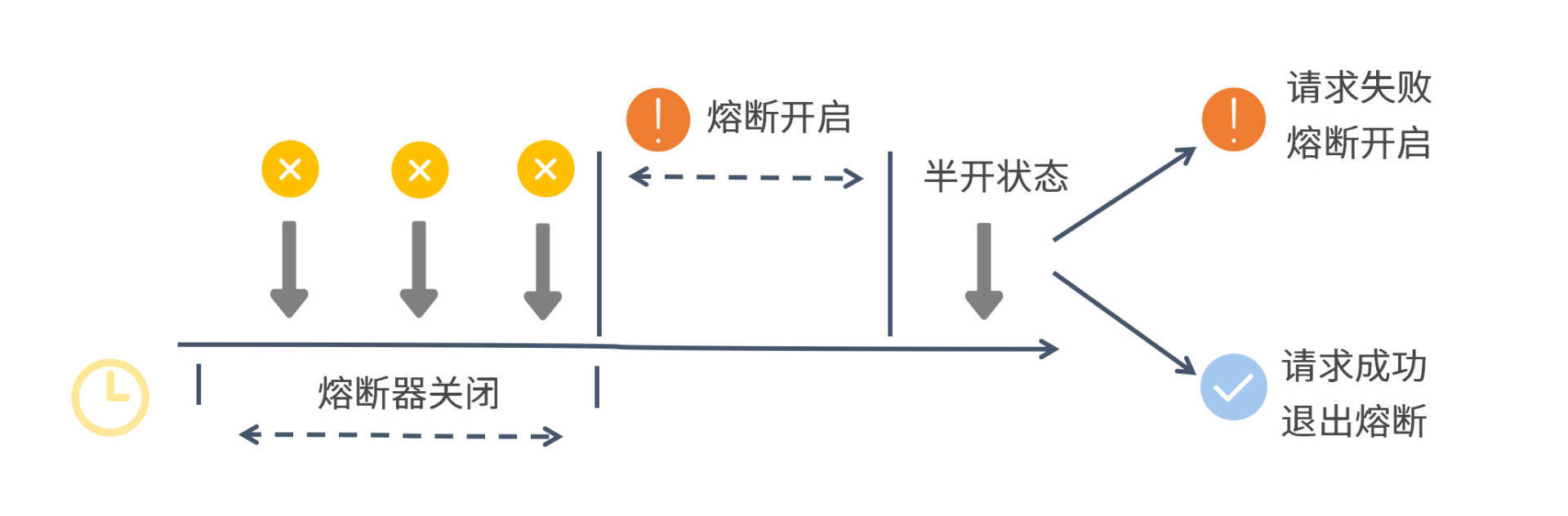
从图中你可以看出,在第一个统计窗口内熔断器是处于关闭状态的,达到熔断判定条件之后,Sentinel 开启了一段熔断窗口。在这段窗口时间内,熔断器是处于开启状态的,这时新的服务请求会执行降级逻辑。待熔断窗口结束,Sentinel 会将熔断器状态置为“半开”状态,这是一个介于完全开启和完全关闭之间的中间态。
在半开状态下,如果有一个新请求过来,那么 Sentinel 会试探性地让这个请求去执行正常的业务逻辑,如果执行成功,那么 Sentinel 将关闭熔断器并退出熔断状态,如果执行失败,那么 Sentinel 将再次开启一个新的熔断窗口。
从这里我们可以得出一个信息,当熔断器处于“半开”状态时,只要下一个请求失败,就立即打回熔断状态,并不需要再次满足熔断规则中设置的各种条件。
五、Sentinel接入Nacos持久化配置
5.1 持久化配置
添加sentinel-nacos依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
添加配置文件
datasource:
# 数据源的key,可以自由命名
depart-flow:
# 指定当前数据源是nacos
nacos:
# 设置Nacos的连接地址、命名空间和Group ID
server-addr: 127.0.0.1:8848
namespace: dev
groupId: SENTINEL_GROUP
#Nacos配置文件格式
data-type: json
# 设置Nacos中配置文件的命名规则
dataId: ${spring.application.name}-flow-rules
# 必填的重要字段,指定当前规则类型是"限流"
rule-type: flow
nacos控制台添加配置文件,注意Data ID和Group需要和yml配置文件中一致

[
{
"resource": "changeValue",
"limitApp":"default",
"grade":1,
"count":1,
"strategy":0,
"controlBehavior":0,
"clusterMode":false
}
]
配置文件说明
resource:资源名称
limitApp:来源应用
grade:阀值类型,0:线程数,1:QPS
count:单机阀值
strategy:流控模式,0:直接,1:关联,2:链路
controlBehavior:流控效果,0:快速失败,1:warmUp,2:排队等待
clusterMode:是否集群
重启测试,访问changeValue接口,发现限流规则生效了。
这种方式还是有点麻烦,可以通过改造Sentinel,实现通过dashboard添加规则,自动同步到nacos,即使项目重启之后,配置也不会被清除。
5.2 sentinel改造
参考Sentinel改造篇
六、Sleuth链路追踪
6.1 引入Sleuth
我们的微服务模块在运行过程中会输出各种各样的日志信息,为了能在日志中打印出特殊的标记,我们需要将 Sleuth 的打标功能集成到各个微服务模块中。
Sleuth 提供了一种无感知的集成方案,只需要添加一个依赖项,再做一些本地启动参数配置就可以开启打标功能了,整个过程不需要做任何的代码改动。所以第一步,我们需要将 Sleuth 的依赖项添加到Customer和Producer服务的 pom.xml 文件中。具体代码如下。
<!-- Sleuth依赖项 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
第二步,我们打开微服务模块的 application.yml 配置文件,在配置文件中添加采样率和每秒采样记录条数。
spring:
sleuth:
sampler:
# 采样率的概率,100%采样
probability: 1.0
# 每秒采样数字最高为1000
rate: 1000
你可以从代码中看到,我在配置文件里设置了一个 probability,它应该是一个 0 到 1 的浮点数,用来表示采样率。我这里设置的 probability 是 1,就表示对请求进行 100% 采样。如果我们把 probability 设置成小于 1 的数,就说明有的请求不会被采样。如果一个请求未被采样,那么它将不会被调用链追踪系统 Track 起来。
你还会在代码中看到 rate 参数,它代表每秒最多可以对多少个 Request 进行采样。这有点像一个“限流”参数,如果超过这个阈值,服务请求仍然会被正常处理,但调用链信息不会被采样。
到这里,我们的 Sleuth 集成工作就已经搞定了。这时你只要启动项目,顺手调用几个 API,就能在控制台的日志信息里看到 Sleuth 默认打印出来的 Trace ID 和 Span ID。比如我这里调用了 Customer 服务,在日志中,你可以看到两串随机生成的数字和字母混合的 ID,其中排在前面的那个 ID 就是 Trace ID,而后面则是 Span ID。
6.2 Sleuth 如何在调用链中传递标记
以 Customer 微服务为例,在我们访问 changeValue接口的时候,用户微服务通过 OpenFeign 组件向 Producer微服务发起了一次请求。
Sleuth 为了将 Trace ID 和 Customer 服务的 Span ID 传递给 Producer微服务,它在 OpenFeign 的环节动了一个手脚。Sleuth 通过 TracingFeignClient 类,将一系列 Tag 标记塞进了 OpenFeign 构造的服务请求的 Header 结构中。我在 TracingFeignClient 的类中打了一个 Debug 断点,将 Request 的 Header 信息打印了出来:
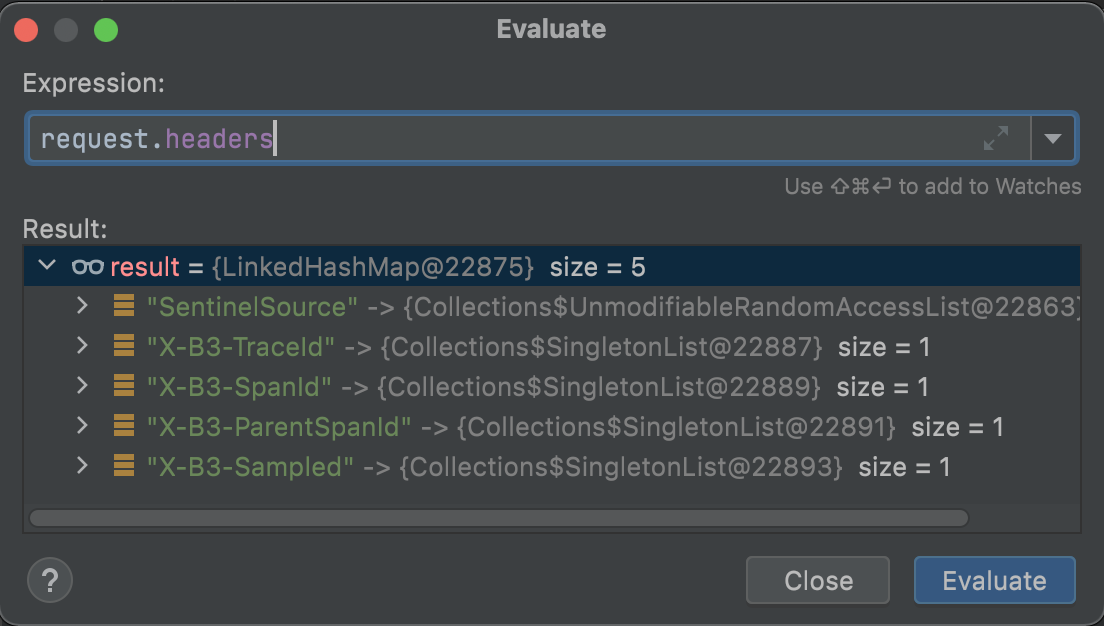
在这个 Header 结构中,我们可以看到有几个以 X-B3 开头的特殊标记,这个 X-B3 就是 Sleuth 的特殊接头暗号。其中 X-B3-TraceId 就是全局唯一的链路追踪 ID,而 X-B3-SpanId 和 X-B3-ParentSpandID 分别是当前请求的单元 ID 和父级单元 ID,最后的 X-B3-Sampled 则表示当前链路是否是一个已被采样的链路。通过 Header 里的这些信息,下游服务就完整地得到了上游服务的情报。
以上是 Sleuth 对 OpenFeign 动的手脚。为了应对调用链中可能出现的各种不同组件,Sleuth 内部构造了各式各样的适配器,用来在不同组件中使用同样的接头暗号“X-B3-*”,这样就可以传递链路追踪的信息。如果你对这部分的源码感兴趣,你可以深入研究 spring-cloud-sleuth-instrumentation 和 spring-cloud-sleuth-brave 两个依赖包的源代码,了解更加详细的实现过程。
6.3 使用 Zipkin 收集并查看链路数据
Zipkin 是一个分布式的 Tracing 系统,它可以用来收集时序化的链路打标数据。通过 Zipkin 内置的 UI 界面,我们可以根据 Trace ID 搜索出一次调用链所经过的所有访问单元,并获取每个单元在当前服务调用中所花费的时间。
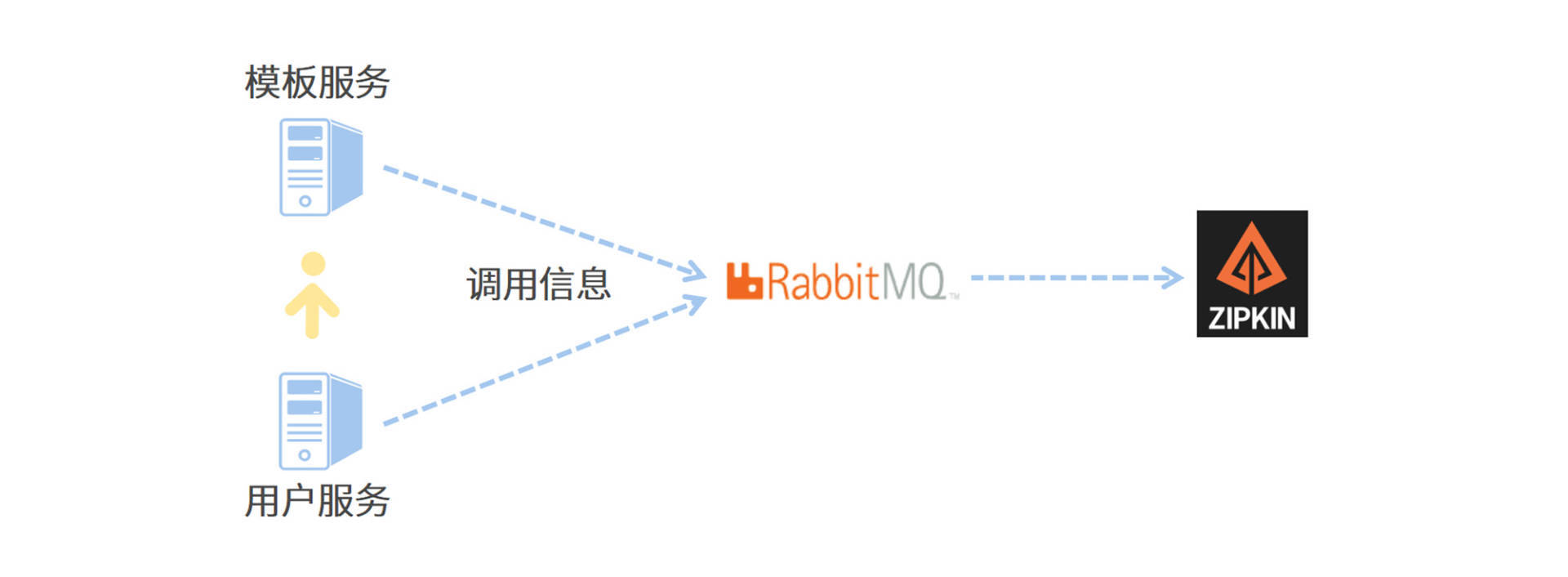
为了搭建一条高可用的链路信息传递通道,我将使用 RabbitMQ 作为中转站,让各个应用服务器将服务调用链信息传递给 RabbitMQ,而 Zipkin 服务器则通过监听 RabbitMQ 的队列来获取调用链数据。相比于让微服务通过 Web 接口直连 Zipkin,使用消息队列可以大幅提高信息的送达率和传递效率。
我画了一张图来帮你理解 Zipkin 和微服务之间是如何通信的,你可以参考一下。
首先,我们要下载一个 Zipkin 的可执行 jar 包,这里我推荐你使用 2.23.9 版本的 Zipkin 组件。你可以通过访问maven 的中央仓库下载 zipkin-server-2.23.9-exec.jar 文件,我已经将版本参数添加到了地址中,不过你可以将地址超链接复制出来,通过修改 URL 中的版本参数来下载指定版本。
搭建 Zipkin 有两种方式,一种是直接下载 Jar 包,这是官方推荐的标准集成方式;另一种是通过引入 Zipkin 依赖项的方式,在本地搭建一个 Spring Boot 版的 Zipkin 服务器。如果你需要对 Zipkin 做定制化开发,那么可以采取后一种方式。
接下来,我们需要在本地启动 Zipkin 服务器。我们打开命令行,在下载下来的 jar 包所在目录执行以下命令,就可以启动 Zipkin 服务器了。
java -jar zipkin-server-2.23.9-exec.jar --zipkin.collector.rabbitmq.addresses=127.0.0.1:5672 --zipkin.collector.rabbitmq.username=guest --zipkin.collector.rabbitmq.password=123456
要注意的是,我在命令行中设置了 zipkin.collector.rabbitmq.addresses 参数,所以 Zipkin 在启动阶段将尝试连接 RabbitMQ,你需要确保 RabbitMQ 始终处于启动状态。Zipkin 已经为我们内置了 RabbitMQ 的默认连接属性,如果没有特殊指定,那么 Zipkin 会使用 guest 默认用户登录 RabbitMQ。如果你想要切换用户、指定默认监听队列或者设置连接参数,那么可以在命令行中添加以下参数进行配置。

启动成功后,你可以在命令行看到 Zipkin 的特色 Logo,以及一行 Serving HTTP 的运行日志。

6.4 传送链路数据到 Zipkin
首先,我们需要在每个微服务模块的 pom.xml 中添加 Zipkin 适配插件和 Stream 的依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
接下来,我们需要将 Zipkin 的配置信息添加到每个微服务模块的 application.yml 文件中。在配置项中,我通过 zipkin.sender.type 属性指定了传输类型为 RabbitMQ,除了 RabbitMQ 以外,Zipkin 适配器还支持 ActiveMQ、Kafka 和直连的方式,我推荐你使用 Kafka 和 RabbitMQ 来保证消息投递的可靠性和高并发性。我还通过 spring.zipkin.rabbitmq 属性声明了消息组件的连接地址和消息投递的队列名称。
spring:
zipkin:
sender:
type: rabbit
rabbitmq:
queue: zipkin
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: 123456
listener: # 这里配置了重试策略
direct:
retry:
enabled: true
有一点你需要注意,在应用中指定的队列名称,一定要同 Zipkin 服务器所指定的队列名称保持一致,否则 Zipkin 无法消费链路追踪数据。到这里,我们就完成了一套完整的链路追踪系统的搭建。
6.5 查看链路追踪信息
你可以在浏览器中打开 localhost:9411 进到 Zipkin 的首页,在首页中你可以通过各种搜索条件的组合,从服务、时间等不同维度查询调用链数据。如果你知道了某个调用链的全局唯一 Trace ID,那么你也可以通过这个 Trace ID 把一整条调用链路查出来。如果某个调用链出现了运行期异常,那么你可以从调用链中轻松看出异常发生在哪个阶段。比如下图中的调用链在 OpenFeign 调用 Customer服务的时候抛出了 RuntimeException,相关 Span 在页面上已被标红,如果你点击 Span 详情,就可以看到具体的 Error 异常提示信息。
Sleuth 配置文件中的参数定义,你能通过传入启动参数的方式,可以对 Zipkin 做一个改造,并使用 MySQL 作为数据源。
https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
这是官方仓库中给的 MySQL 改造的脚本,创建一个 zipkin 的 db 库;之后可以从 https://github.com/openzipkin/zipkin/blob/16857b6cc3/zipkin-server/src/main/resources/zipkin-server-shared.yml 配置文件中看到 mysql 的配置项,然后对照着之前老师给的命令,添加上 MySQL 的即可,可以参考如下命令
java -jar zipkin-server-2.23.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=123456 --MYSQL_DB=zipkin --zipkin.collector.rabbitmq.addresses=127.0.0.1:5672 --zipkin.collector.rabbitmq.username=guest --zipkin.collector.rabbitmq.password=123456